











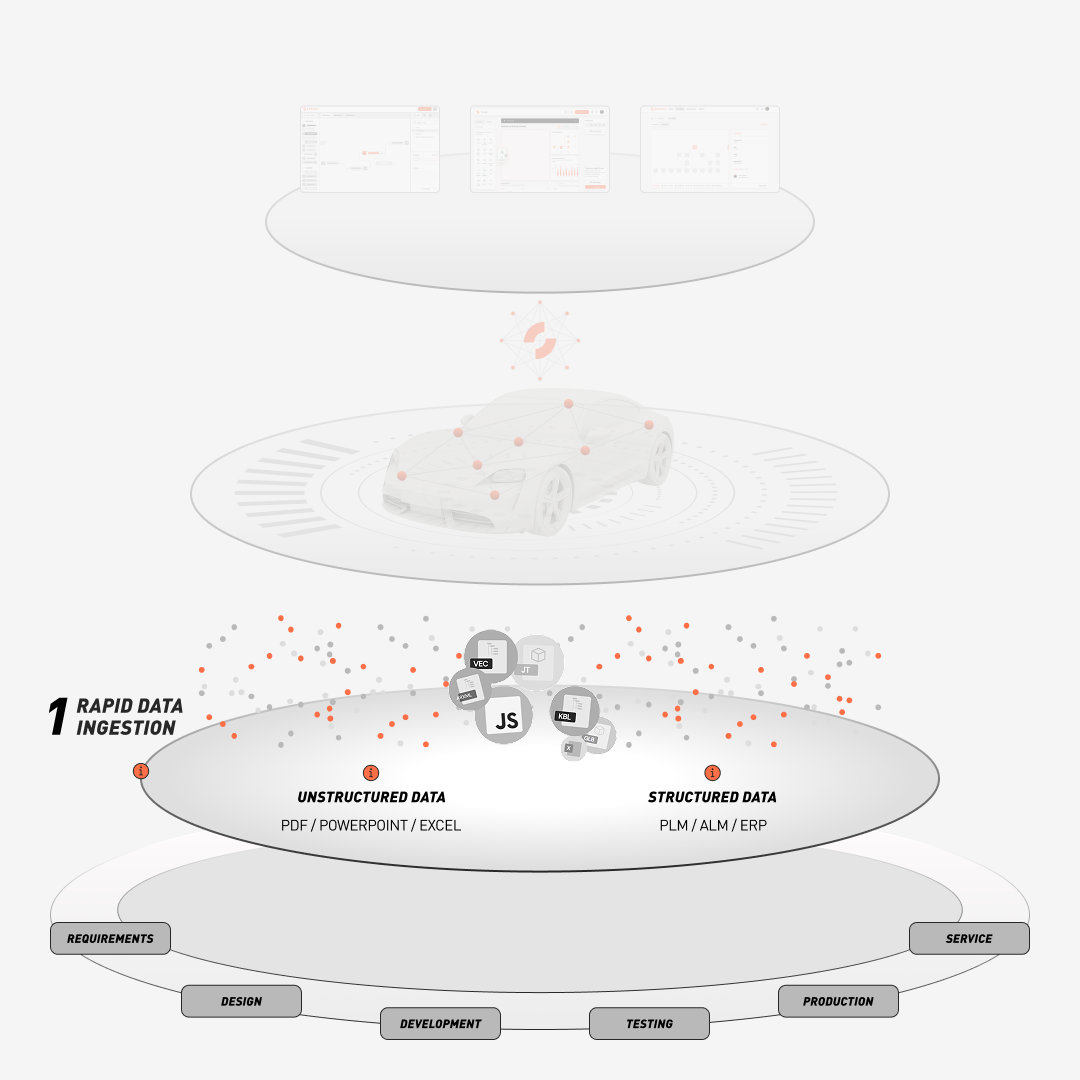
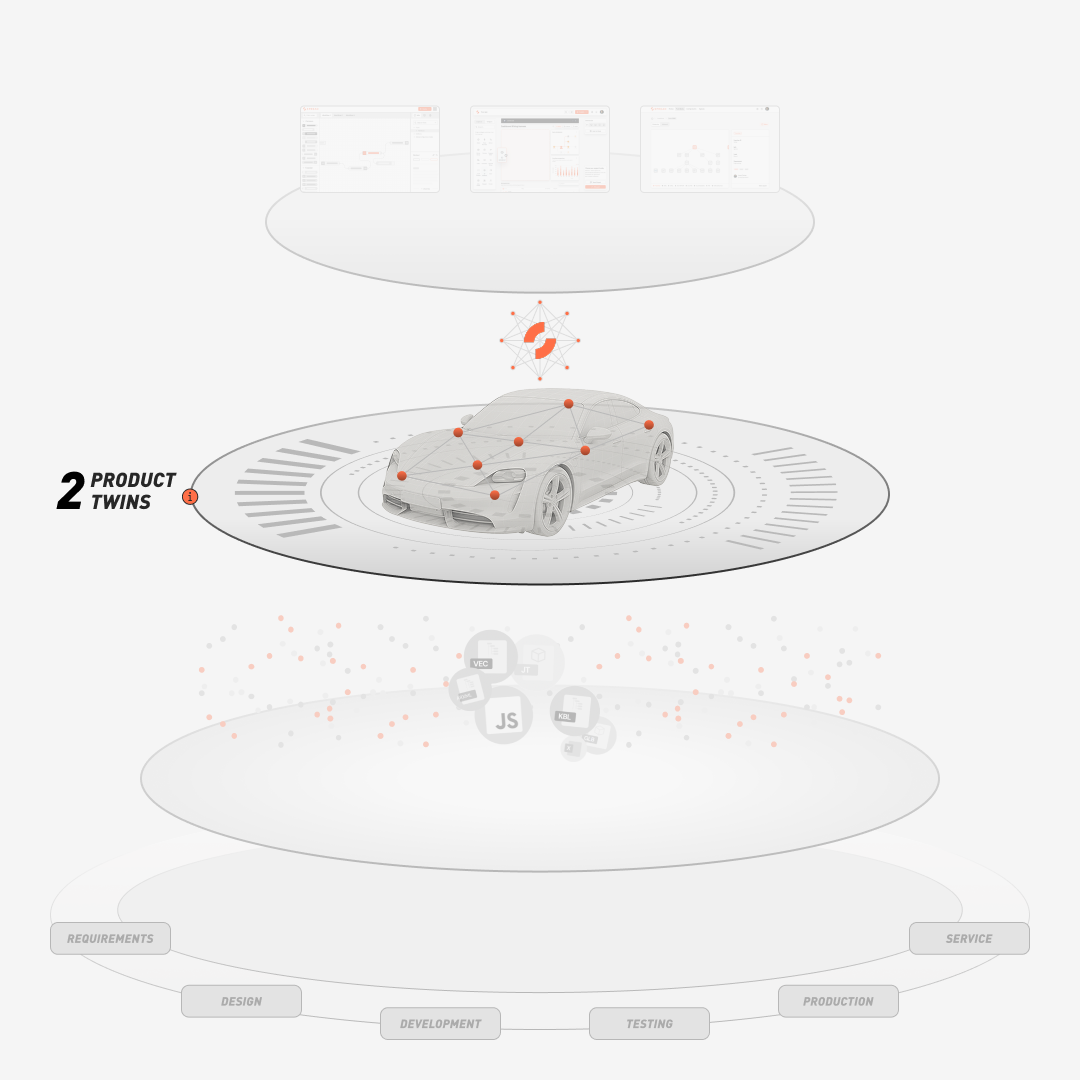
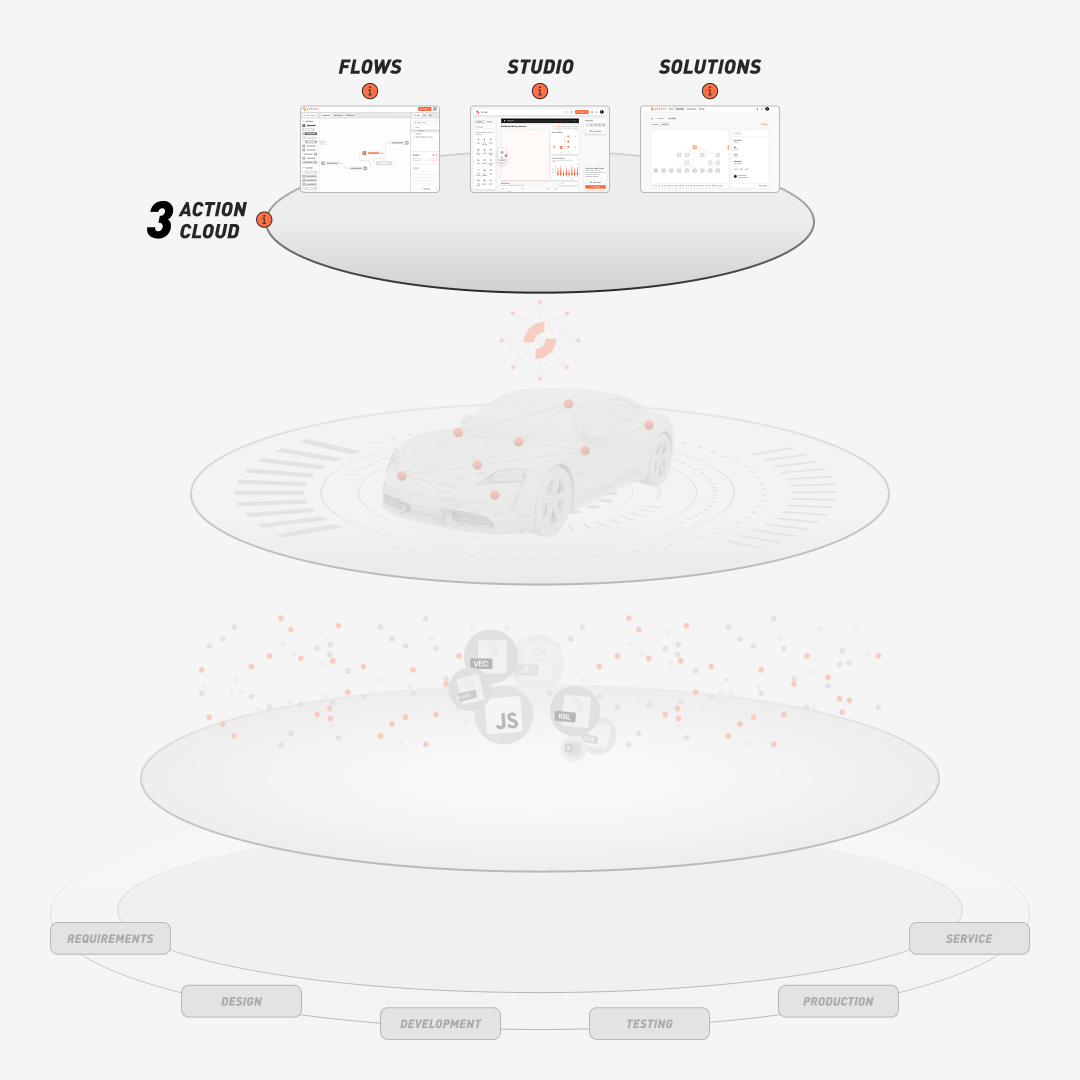












Accelerate time-to-market of software-defined vehicles
SPREAD helps accelerate development, reduce variant complexity, and secure SOPs by visualizing dependencies across functions, components, and signals.
In production and aftermarket, it reduces repair costs and improves yields through guided, VIN-specific troubleshooting and intuitive onboarding.

